
 Твитнуть
Твитнуть
1) вы, атеисты, уже задолбали про враньё. какое враньё? всё вам объяснил: какая разница, какое название у программы - АльфаЗеро или АльфаГоЗеро? они все только программы. почему что ни атеист - то хам? программа у вас, видимо, такая...
ведите себя прилично, вы не в своём атеистическом обезьяннике
2) ну, мнение гуманитария Каспарова лично мне не очень интересно. было бы интереснее, если бы вы выложили мнение программиста, который сказал бы, что АльфаЗеро думает сам; а не согласно программе, которая прописана так, что у не-программистов создаётся впечатление, будто АльфаЗеро думает "сама"(это как какие-нибудь пигмеи в джунглях думают, что автомобиль едет сам)
3) а вот рассуждения программиста(а не восторженного гуманитария типа Каспарова), который относится к АльфаЗеро сугубо как к железяке с заложенной программой на "само"обучение:
"Алгоритм AlphaZero - это более общая версия алгоритма AlphaGo Zero. Вместо внешней оценочной функции и эвристик ходов AlphaZero обращается к глубокой нейронной сети "(p, v) = fθ(s)" с параметром θ. Эта нейронная сеть принимает на входе позицию на доске s, а на выходе предоставляет вектор эффективностей ходов p с компонентами "pa = Pr(a|s)" для каждого действия a, и скалярную переменную v вычисляющую исход z из позиции s, "v ≈ E[z|s]".
Вместо альфа-бета поиска с предметно-ориентированными адаптациями AlphaZero использует для поиска дерево Монте-Карло. Каждый поиск состоит из серии симуляций игр, которые обходят дерево от корня к ветвям. Каждая симуляция выбирает для каждого состояния s ход a с наименьшим количеством посещений, наибольшей эффективностью и наибольшим значением, в соответствии с текущим fθ. Поиск возвращает вектор π, представляющий эффективности ходов.
Параметр θ получен с помощью самообучения, его начальное значение было выбрано случайно. Выбора ходов для каждого игрока происходил с помощью поиска в дереве Монте-Карло. В конце каждой игры конечная позиция sT оценивалась в соответствии с правилами исхода игры: -1 для проигрыша, 0 для ничьей и +1 для победы. Параметр θ обновлялся, чтобы минимизировать ошибку между предсказанным исходом vt и реальным исходом z, также параметр θ обновлялся для максимизации сходства вектора pt к полученным в результате поиска вероятностям πt. В частности, параметр θ отрегулирован градиентным спуском функции l, которая состоит из суммы квадрата отклонения ошибки и потери энтропии.
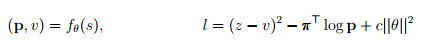
где c - параметр контролирующий уровень регуляризации весов L2. Обновленные параметры затем используются в последующих играх.
AlphaGo Zero настраивает гипер-параметр для поиска с помощью оптимизации Байеса. А в AlphaZero мы повторно используем один и тот же гипер-параметр для всех игр без подстройки под конкретную игру. Единственное исключение - это шум, который мы добавили, чтобы обеспечить разнообразие. Шум пропорционален типичному количеству возможных ходов для данного типа игры. Как и в AlphaGo Zero в AlphaZero состояние доски закодировано пространственными плоскостями, основанным только на базовых правилах данной игры. Действия закодированы аналогично пространственными плоскостями или плоским вектором, которые также основаны на базовых правилах игры.
Мы применили AlphaZero к шахматам, сеги и го. Программа имеет те же самые настройки, архитектуру нейронной сети и гипер-параметр для всех трех игр.
В основе AlphaZero лежит перебор ходов, но классические программы перебирают практически все подряд, а AlphaZero выбирает только между самыми эффективными ходами (грубо говоря, перебор 10 млн тупых ходов против перебора 70 тыс умных)".
https://pikabu.ru/story/perevod_orig...matakh_5545165
ведите себя прилично, вы не в своём атеистическом обезьяннике
2) ну, мнение гуманитария Каспарова лично мне не очень интересно. было бы интереснее, если бы вы выложили мнение программиста, который сказал бы, что АльфаЗеро думает сам; а не согласно программе, которая прописана так, что у не-программистов создаётся впечатление, будто АльфаЗеро думает "сама"(это как какие-нибудь пигмеи в джунглях думают, что автомобиль едет сам)
3) а вот рассуждения программиста(а не восторженного гуманитария типа Каспарова), который относится к АльфаЗеро сугубо как к железяке с заложенной программой на "само"обучение:
"Алгоритм AlphaZero - это более общая версия алгоритма AlphaGo Zero. Вместо внешней оценочной функции и эвристик ходов AlphaZero обращается к глубокой нейронной сети "(p, v) = fθ(s)" с параметром θ. Эта нейронная сеть принимает на входе позицию на доске s, а на выходе предоставляет вектор эффективностей ходов p с компонентами "pa = Pr(a|s)" для каждого действия a, и скалярную переменную v вычисляющую исход z из позиции s, "v ≈ E[z|s]".
Вместо альфа-бета поиска с предметно-ориентированными адаптациями AlphaZero использует для поиска дерево Монте-Карло. Каждый поиск состоит из серии симуляций игр, которые обходят дерево от корня к ветвям. Каждая симуляция выбирает для каждого состояния s ход a с наименьшим количеством посещений, наибольшей эффективностью и наибольшим значением, в соответствии с текущим fθ. Поиск возвращает вектор π, представляющий эффективности ходов.
Параметр θ получен с помощью самообучения, его начальное значение было выбрано случайно. Выбора ходов для каждого игрока происходил с помощью поиска в дереве Монте-Карло. В конце каждой игры конечная позиция sT оценивалась в соответствии с правилами исхода игры: -1 для проигрыша, 0 для ничьей и +1 для победы. Параметр θ обновлялся, чтобы минимизировать ошибку между предсказанным исходом vt и реальным исходом z, также параметр θ обновлялся для максимизации сходства вектора pt к полученным в результате поиска вероятностям πt. В частности, параметр θ отрегулирован градиентным спуском функции l, которая состоит из суммы квадрата отклонения ошибки и потери энтропии.
где c - параметр контролирующий уровень регуляризации весов L2. Обновленные параметры затем используются в последующих играх.
AlphaGo Zero настраивает гипер-параметр для поиска с помощью оптимизации Байеса. А в AlphaZero мы повторно используем один и тот же гипер-параметр для всех игр без подстройки под конкретную игру. Единственное исключение - это шум, который мы добавили, чтобы обеспечить разнообразие. Шум пропорционален типичному количеству возможных ходов для данного типа игры. Как и в AlphaGo Zero в AlphaZero состояние доски закодировано пространственными плоскостями, основанным только на базовых правилах данной игры. Действия закодированы аналогично пространственными плоскостями или плоским вектором, которые также основаны на базовых правилах игры.
Мы применили AlphaZero к шахматам, сеги и го. Программа имеет те же самые настройки, архитектуру нейронной сети и гипер-параметр для всех трех игр.
В основе AlphaZero лежит перебор ходов, но классические программы перебирают практически все подряд, а AlphaZero выбирает только между самыми эффективными ходами (грубо говоря, перебор 10 млн тупых ходов против перебора 70 тыс умных)".
https://pikabu.ru/story/perevod_orig...matakh_5545165




 .
.
Комментарий