
 Твитнуть
Твитнуть
************
Как работает фильтрация в Web
Web-фильтры отличаются по сложности, детальности, точности, местонахождению и прозрачности. Простые Web-фильтры реализовать легко, но они работают довольно грубо.
К тому же мотивированные пользователи, как правило, с большей готовностью стремятся обнаружить и обойти их.
Черные списки IP-адресов и URL
Простейшие Web-фильтры используют черные списки IP-адресов. Основное их преимущество скорость. Фактически это быстрый поиск в таблице. Именно благодаря высокой скорости такого подхода Web-фильтрацию можно выполнять в сети в «точках блокировки», где собирается трафик, например в шлюзах между смежными национальными сетями. Однако простота черных списков обусловливает и два их главных недостатка. Во-первых, для непрерывного обновления черного списка требуются большие ресурсы. Во-вторых, черный список IP-адресов работает слишком грубо фильтр либо блокирует, либо разрешает весь Web-контент, получаемый с данного IP-адреса.
Черные списки URL обеспечивают большую детализацию и зачастую реализованы на серверах DNS, которые определяют IP-адреса по именам соответствующих доменов. Когда DNS-сервер получает запрос на разрешение имени, он проверяет наличие данного URL в черном списке. Если этот URL есть в списке, сервер вернет некорректный IP-адрес или IP-адрес по умолчанию. Черный список URL обладает теми же недостатками, что и список IP-адресов, их поддержка и обновление требуют значительных усилий.
Оба списка можно использовать для фильтров, размещаемых на прокси-сервере, которые часто применяются для локального кэширования Web-контента. В такой кэш-памяти хранится недавно запрошенный контент, и если пользователям он снова требуется, то он передается из кэша прокси-сервера, а не с оригинального сервера. Поскольку весь Web-контент проходит через прокси-сервер, то последний становится очень удобным местом для фильтрации.
При всех обращениях в Web-фильтры, размещаемые на прокси-сервере, проверяют попадание адреса в черные списки IP-адресов или URL. При обнаружении совпадения фильтр может вернуть «заблокированную страницу» с сообщением об ошибке. В некоторых странах, например в Китае и Иране, пошли еще дальше и блокируют URL, содержащие запрещенные ключевые слова. Однако ключевые слова не всегда точно отражают содержимое соответствующей Web-страницы, например, слово sex в URL содержат многие другие виды сайтов, помимо порнографических, и, наоборот, блокировка URL с таким словом не всегда позволяет отследить порнографические сайты.
Фильтрация контента
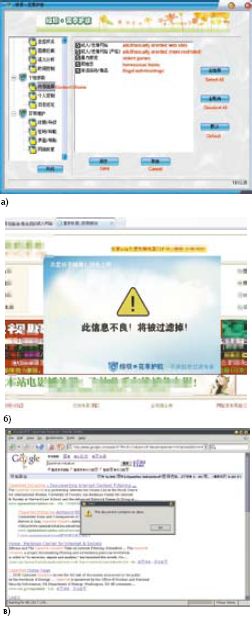 Фильтрация контента в режиме реального времени на прокси-сервере или на Web-клиенте имеет два важных преимущества перед черными списками IP-адресов или URL. Во-первых, фильтр анализирует Web-контент, когда происходит обращение к странице, и не требует предварительной установки черного списка. Во-вторых, решение о фильтрации принимается для отдельных Web-страниц или даже для элементов внутри них. Однако к фильтру контента предъявляются два сложных и иногда взаимоисключающих требования: он должен обладать достаточным «интеллектом» для того, чтобы распознать нежелательную страницу или контент внутри страницы, и при этом работать довольно быстро. Фильтры контента, как правило, используют методы машинного обучения и искусственного интеллекта для того, чтобы установить, к какой из предопределенных категорий относится данная Web-страница (рис. 1a). Пользователи или сетевые администраторы могут настроить фильтр так, чтобы он блокировал или разрешал доступ для каждой из категорий отдельно. При этом немаловажное значение имеет скорость работы, поскольку пользователям не хватает терпения, и они уходят с сайта, если тот возвращает запрошенный контент слишком медленно.
Фильтрация контента в режиме реального времени на прокси-сервере или на Web-клиенте имеет два важных преимущества перед черными списками IP-адресов или URL. Во-первых, фильтр анализирует Web-контент, когда происходит обращение к странице, и не требует предварительной установки черного списка. Во-вторых, решение о фильтрации принимается для отдельных Web-страниц или даже для элементов внутри них. Однако к фильтру контента предъявляются два сложных и иногда взаимоисключающих требования: он должен обладать достаточным «интеллектом» для того, чтобы распознать нежелательную страницу или контент внутри страницы, и при этом работать довольно быстро. Фильтры контента, как правило, используют методы машинного обучения и искусственного интеллекта для того, чтобы установить, к какой из предопределенных категорий относится данная Web-страница (рис. 1a). Пользователи или сетевые администраторы могут настроить фильтр так, чтобы он блокировал или разрешал доступ для каждой из категорий отдельно. При этом немаловажное значение имеет скорость работы, поскольку пользователям не хватает терпения, и они уходят с сайта, если тот возвращает запрошенный контент слишком медленно.
Для определения категории Web-страницы интеллектуальные фильтры контента анализируют различные ее элементы, в том числе метаданные, ссылки, текст, изображения и скрипты. Метаданные в заголовке Web-документа могут содержать информацию об авторстве и ключевых словах.
Анализ ссылок основывается на принципе «виновности в соучастии». Как правило, страницы имеют ссылки на страницы одного и того же типа. Например, новостной сайт, скорее всего, содержит ссылки на другие новостные сайты. Ссылки, приводимые на странице, могут многое сказать о ее теме.
Текстовый анализ имеет большое значение для фильтров контента, поскольку многие Web-страницы в основном текстовые. Как правило, фильтры контента выполняют грамматический разбор текста, находят ключевые слова и применяют методы машинного обучения для того, чтобы определить наиболее подходящую для данной страницы категорию. Однако этот подход не совершенен без семантического анализа, поскольку иногда трудно понять разные контексты например, преследует ли страница с сексуальным контентом образовательные или порнографические цели.
Как работает фильтрация в Web
Web-фильтры отличаются по сложности, детальности, точности, местонахождению и прозрачности. Простые Web-фильтры реализовать легко, но они работают довольно грубо.
К тому же мотивированные пользователи, как правило, с большей готовностью стремятся обнаружить и обойти их.
Черные списки IP-адресов и URL
Простейшие Web-фильтры используют черные списки IP-адресов. Основное их преимущество скорость. Фактически это быстрый поиск в таблице. Именно благодаря высокой скорости такого подхода Web-фильтрацию можно выполнять в сети в «точках блокировки», где собирается трафик, например в шлюзах между смежными национальными сетями. Однако простота черных списков обусловливает и два их главных недостатка. Во-первых, для непрерывного обновления черного списка требуются большие ресурсы. Во-вторых, черный список IP-адресов работает слишком грубо фильтр либо блокирует, либо разрешает весь Web-контент, получаемый с данного IP-адреса.
Черные списки URL обеспечивают большую детализацию и зачастую реализованы на серверах DNS, которые определяют IP-адреса по именам соответствующих доменов. Когда DNS-сервер получает запрос на разрешение имени, он проверяет наличие данного URL в черном списке. Если этот URL есть в списке, сервер вернет некорректный IP-адрес или IP-адрес по умолчанию. Черный список URL обладает теми же недостатками, что и список IP-адресов, их поддержка и обновление требуют значительных усилий.
Оба списка можно использовать для фильтров, размещаемых на прокси-сервере, которые часто применяются для локального кэширования Web-контента. В такой кэш-памяти хранится недавно запрошенный контент, и если пользователям он снова требуется, то он передается из кэша прокси-сервера, а не с оригинального сервера. Поскольку весь Web-контент проходит через прокси-сервер, то последний становится очень удобным местом для фильтрации.
При всех обращениях в Web-фильтры, размещаемые на прокси-сервере, проверяют попадание адреса в черные списки IP-адресов или URL. При обнаружении совпадения фильтр может вернуть «заблокированную страницу» с сообщением об ошибке. В некоторых странах, например в Китае и Иране, пошли еще дальше и блокируют URL, содержащие запрещенные ключевые слова. Однако ключевые слова не всегда точно отражают содержимое соответствующей Web-страницы, например, слово sex в URL содержат многие другие виды сайтов, помимо порнографических, и, наоборот, блокировка URL с таким словом не всегда позволяет отследить порнографические сайты.
Фильтрация контента
Фильтрация контента в режиме реального времени на прокси-сервере или на Web-клиенте имеет два важных преимущества перед черными списками IP-адресов или URL. Во-первых, фильтр анализирует Web-контент, когда происходит обращение к странице, и не требует предварительной установки черного списка. Во-вторых, решение о фильтрации принимается для отдельных Web-страниц или даже для элементов внутри них. Однако к фильтру контента предъявляются два сложных и иногда взаимоисключающих требования: он должен обладать достаточным «интеллектом» для того, чтобы распознать нежелательную страницу или контент внутри страницы, и при этом работать довольно быстро. Фильтры контента, как правило, используют методы машинного обучения и искусственного интеллекта для того, чтобы установить, к какой из предопределенных категорий относится данная Web-страница (рис. 1a). Пользователи или сетевые администраторы могут настроить фильтр так, чтобы он блокировал или разрешал доступ для каждой из категорий отдельно. При этом немаловажное значение имеет скорость работы, поскольку пользователям не хватает терпения, и они уходят с сайта, если тот возвращает запрошенный контент слишком медленно.Для определения категории Web-страницы интеллектуальные фильтры контента анализируют различные ее элементы, в том числе метаданные, ссылки, текст, изображения и скрипты. Метаданные в заголовке Web-документа могут содержать информацию об авторстве и ключевых словах.
Анализ ссылок основывается на принципе «виновности в соучастии». Как правило, страницы имеют ссылки на страницы одного и того же типа. Например, новостной сайт, скорее всего, содержит ссылки на другие новостные сайты. Ссылки, приводимые на странице, могут многое сказать о ее теме.
Текстовый анализ имеет большое значение для фильтров контента, поскольку многие Web-страницы в основном текстовые. Как правило, фильтры контента выполняют грамматический разбор текста, находят ключевые слова и применяют методы машинного обучения для того, чтобы определить наиболее подходящую для данной страницы категорию. Однако этот подход не совершенен без семантического анализа, поскольку иногда трудно понять разные контексты например, преследует ли страница с сексуальным контентом образовательные или порнографические цели.

 Мы тут не хакеры и не воры, как тебе хочется нас видеть. Но, знаешь, если эту инфу кинуть на какой-нибудь хакерский форум, интересно, что они с тобой сделают?
Мы тут не хакеры и не воры, как тебе хочется нас видеть. Но, знаешь, если эту инфу кинуть на какой-нибудь хакерский форум, интересно, что они с тобой сделают?
Комментарий